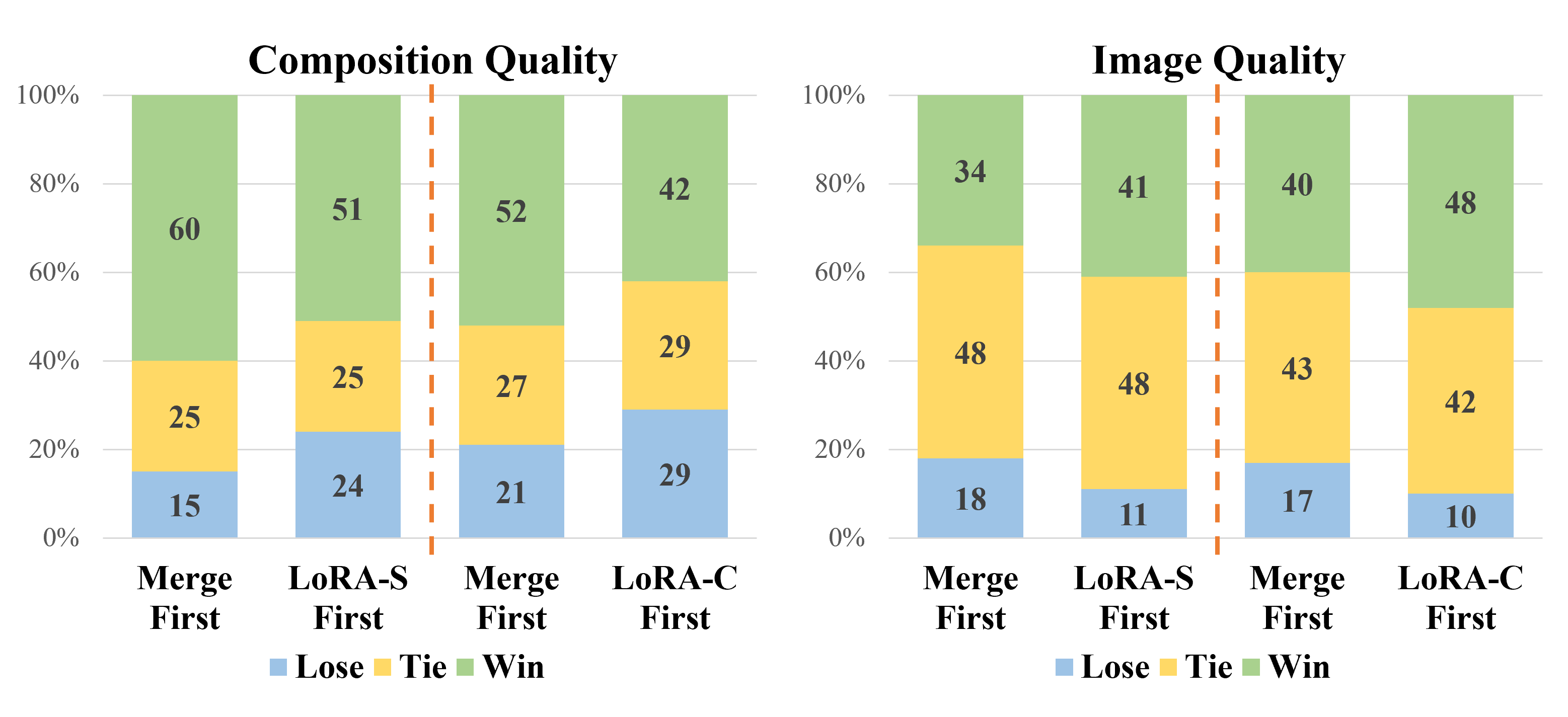Methods of Multi-LoRA Composition
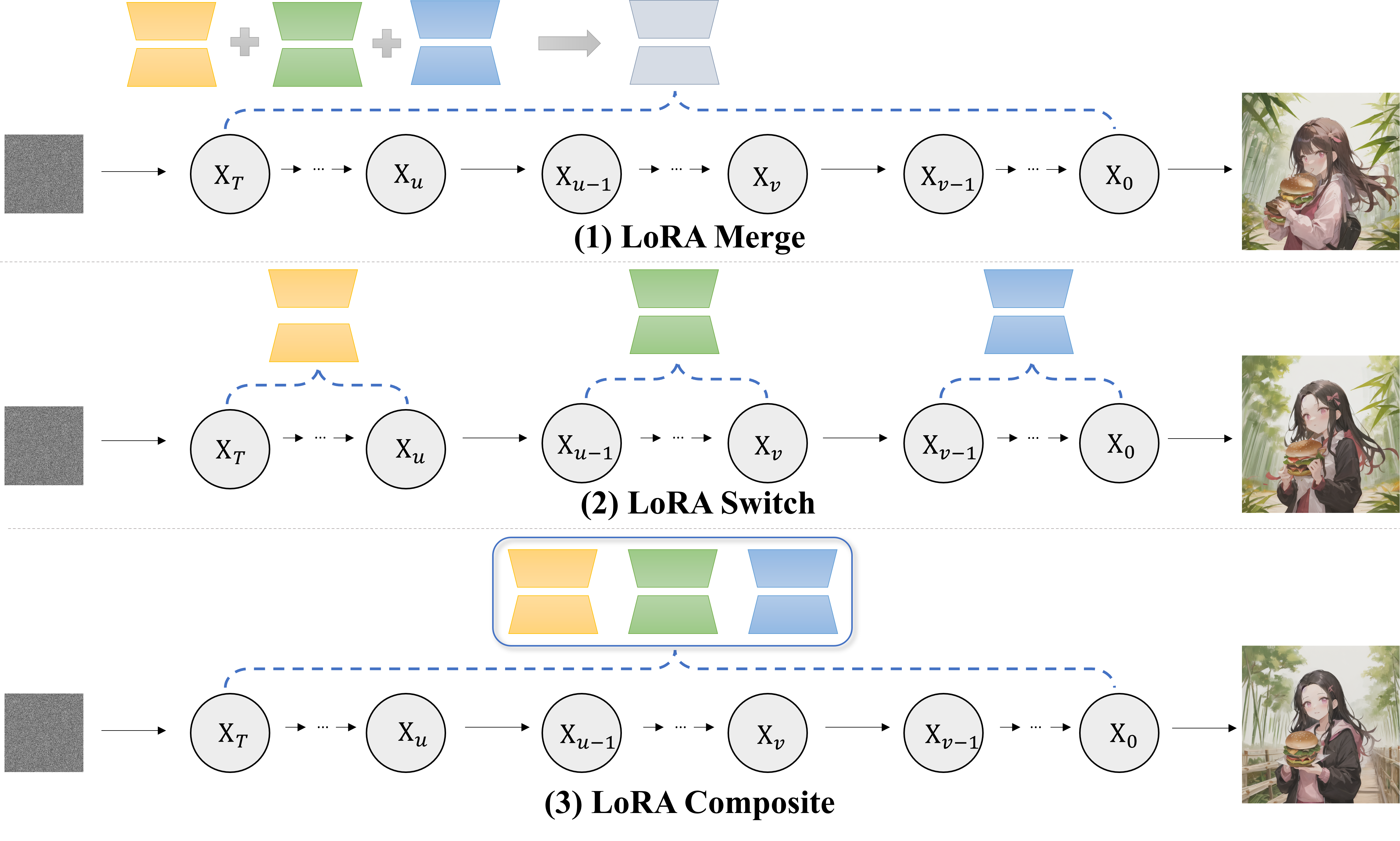
- LoRA Merge:
- Prevalent approach to integrating multiple elements in a unified way in an image.
- It is realized by linearly combining multiple LoRAs to synthesize a unified LoRA, subsequently plugged into the text-to-image model.
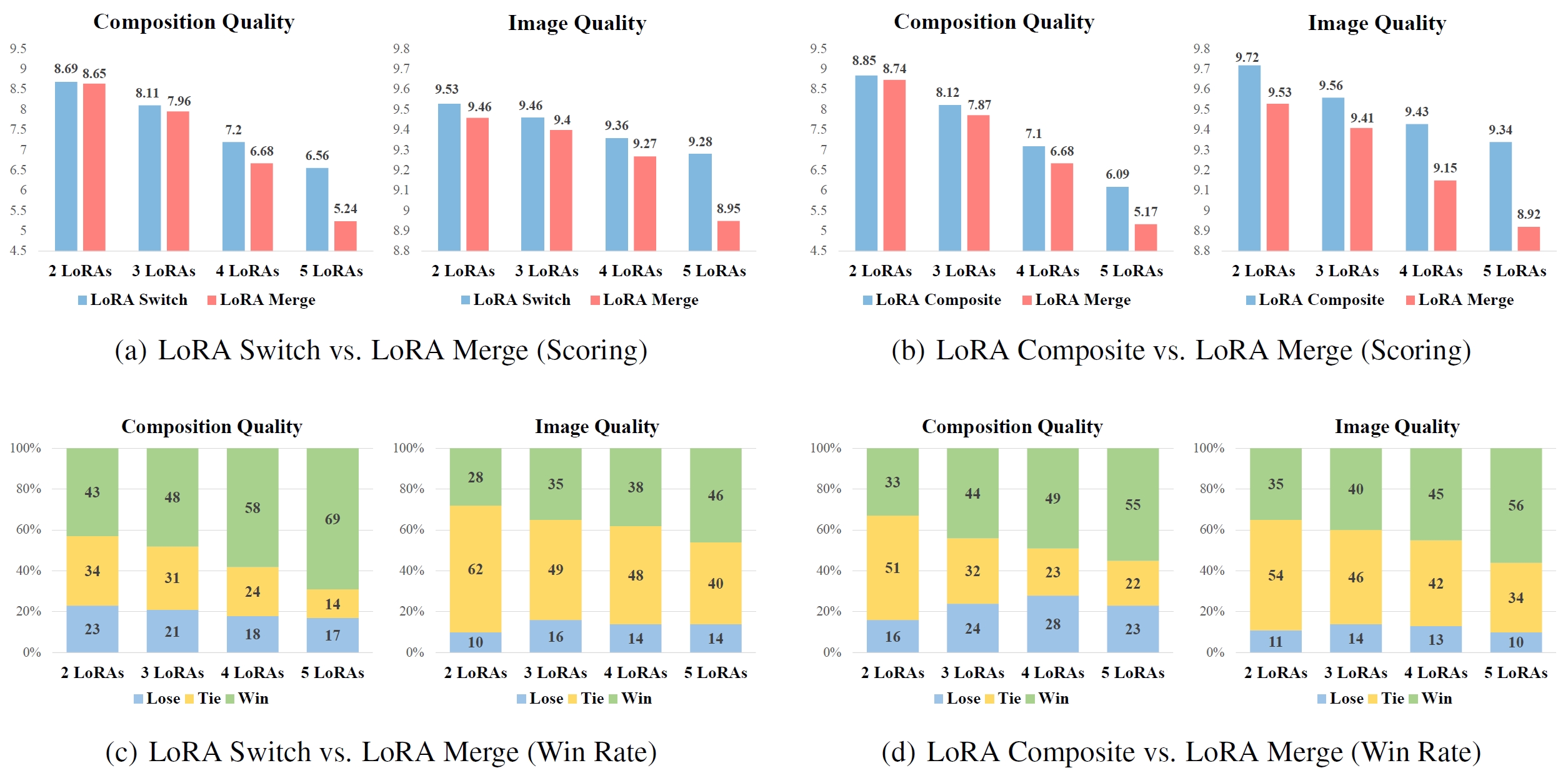
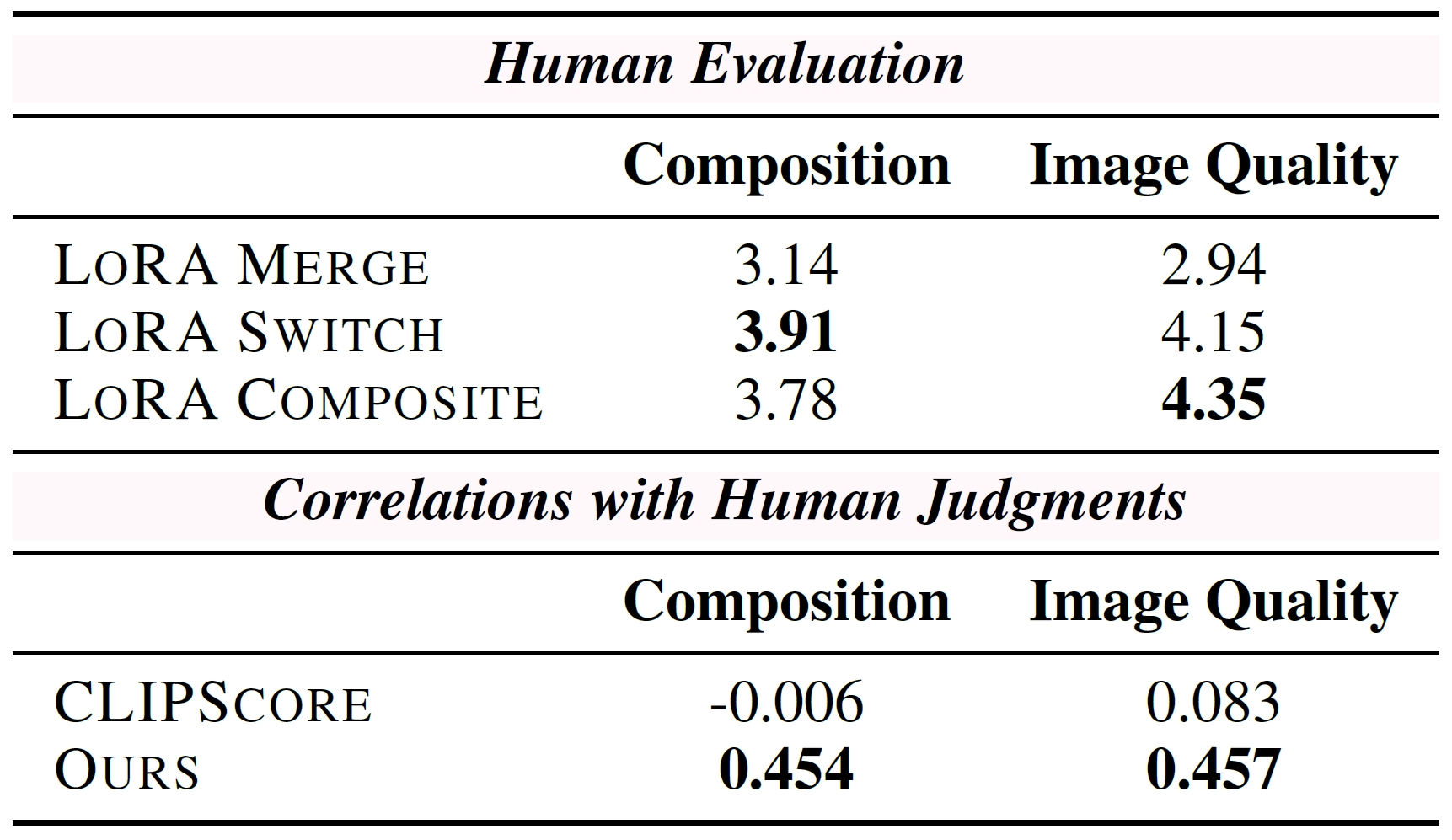
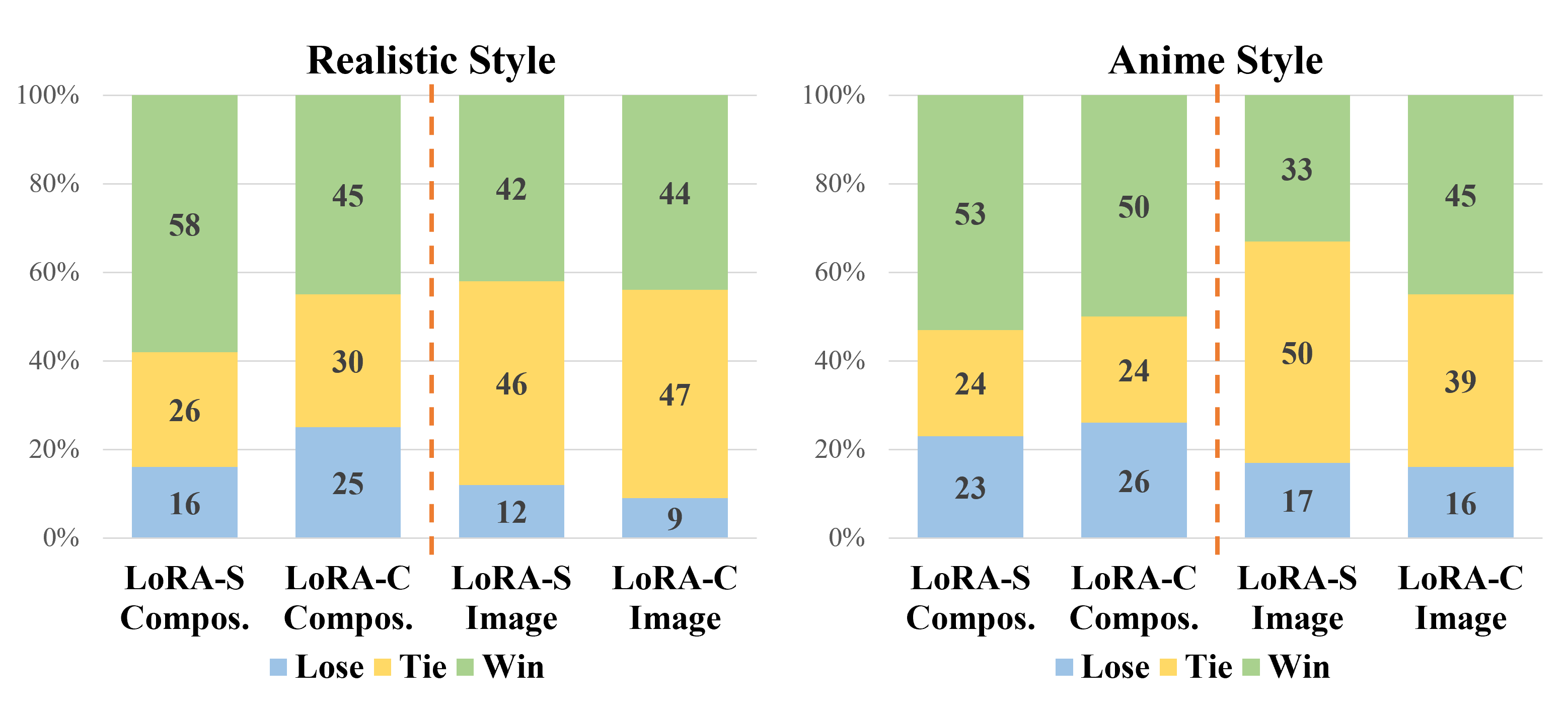
- LoAR Merge completely overlooks the interaction with the diffusion model during the generative process, resulting in the deformation of the hamburger and fingers in the Figure.
- LoRA Switch (LoRA-S):
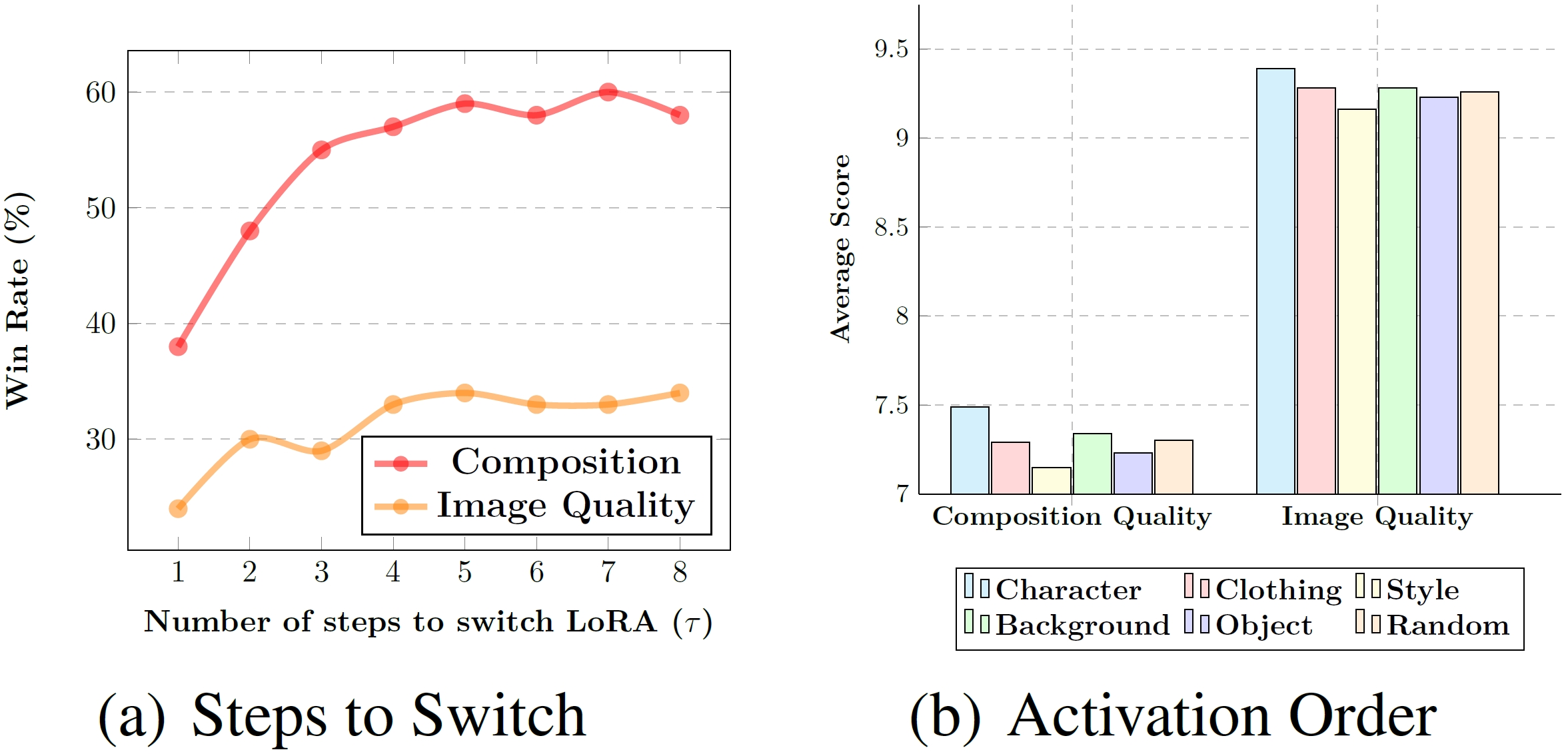
- To explore activating a single LoRA in each denoising step, we propose LoRA Switch.
- This method introduces a dynamic adaptation mechanism within diffusion models by sequentially activating individual LoRAs at designated intervals throughout the decoding process.
- As illustrated in the Figure, each LoRA is represented by a unique color corresponding to a specific element, with only one LoRA engaged per denoising step.
- LoRA Composite (LoRA-C):
- To explore incorporating all LoRAs at each timestep without merging weight matrices, we propose LoRA Composite.
- It involves calculating both unconditional and conditional score estimates for each LoRA individually at each step.
- By aggregating these scores, the technique ensures balanced guidance throughout the image generation process, facilitating the cohesive integration of all elements represented by different LoRAs.